Yann Herklotz has added hyperblock scheduling to his verified high-level synthesis (HLS) tool called Vericert, and I’m very pleased that our paper about this work has been accepted to appear at PLDI 2024 this June.
This paper was our “difficult second album”, in the sense that we’d already published a paper about the first version of Vericert in OOPSLA 2021, so we no longer had such a crisp “novelty” story. That is, we were no longer presenting “the first mechanically verified HLS tool”, but rather “a verified HLS tool that generates more efficient hardware designs”. I say “difficult” not because we had particular trouble getting the paper accepted – PLDI 2024 was actually the first venue we tried – but because the amount of work Yann did to add hyperblock scheduling to Vericert was about twice as much as the work he did to produce the entire first version of Vericert!
So what’s hyperblock scheduling all about, and why has it been added to an HLS tool?
As a quick primer: HLS is the process of compiling software (written in C, say) not into assembly language for a general-purpose processor, but into a design (written in Verilog, say) for a fixed-function piece of hardware that behaves like the input software. It’s popular these days because offloading computation to custom hardware accelerators is a great way to improve performance and energy efficiency, but writing those accelerators manually is laborious and error-prone. Better to specify the computation in software and then generate the hardware accelerator automatically via HLS!
Unfortunately, today’s crop of HLS tools are known to be a bit buggy, which makes them ill suited for use in a safety- or security-critical setting. This motivated the development of Vericert v1.0 – the first HLS tool mechanically proven (in Coq) never to produce a Verilog design that behaves differently from the C program it is given.
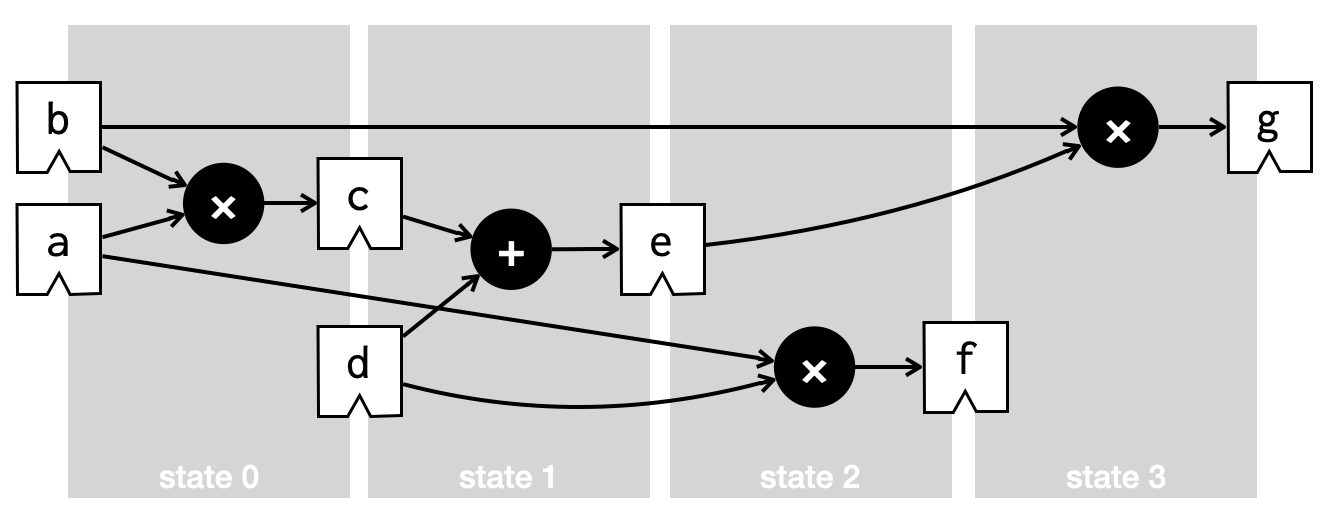
Although Vericert v1.0 had a solid correctness story, its performance was quite underwhelming compared to that of the existing (unverified) HLS tools. Its main shortcoming was that it failed to exploit the inherently parallel nature of hardware. Instead, it produced hardware that performed just one operation per clock cycle. Essentially, it took the input C program, transformed that C program into a control-flow graph (CFG), and turned that CFG into a state machine, with just one instruction per state.
More concretely, if Vericert v1.0 were given a piece of straight-line C code like this:
c = a * b;
e = c + d;
f = a * d;
g = e * b;
it would produce Verilog that looks (roughly) like this:
initial state = 0;
always @ (posedge clk)
case (state)
0: begin c = a * b; state = 1; end
1: begin e = c + d; state = 2; end
2: begin f = a * d; state = 3; end
3: begin g = e * b; end
endcase
and which would execute over four clock cycles (states) like this:
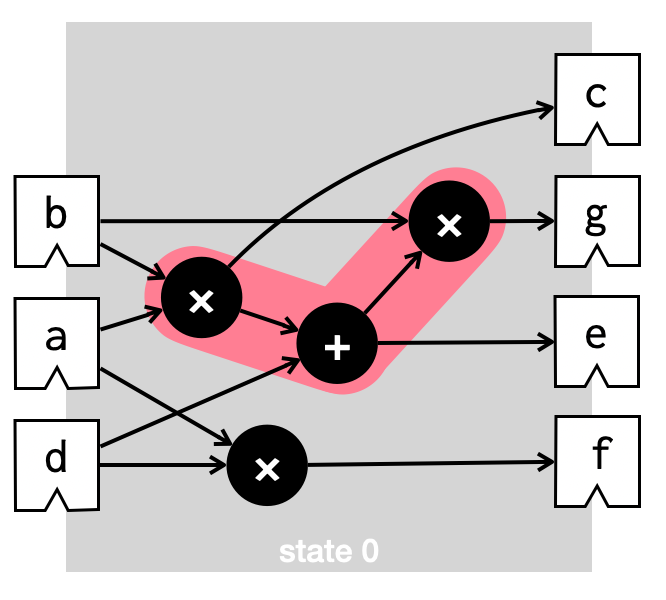
Now, we’d like to pack more computation into each clock cycle. We could do this really naively by packing everything into a single clock cycle. That would produce Verilog that looks (roughly) like this:
initial state = 0;
always @ (posedge clk)
case (state)
0: begin c = a * b;
e = c + d;
f = a * d;
g = e * b; end
endcase
and which would execute, in a single clock cycle, like this:

Although our computation now requires fewer clock cycles, our hardware is still not good because its critical path (highlighted in pink above) is too long. That is, the clock frequency would have to be really low in order to allow time for a multiplication, then an addition, and then a second multiplication all to complete within a single cycle.
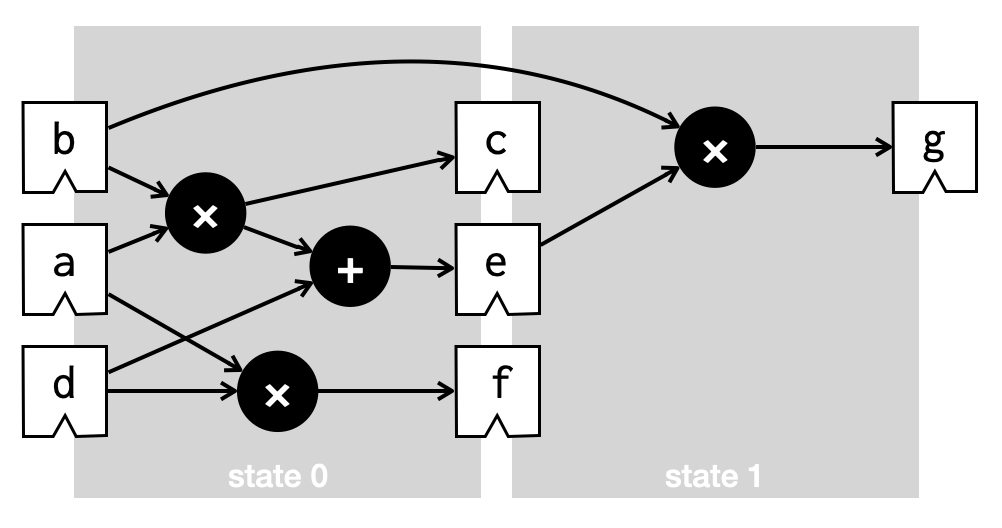
What HLS tools do in practice, then, is (1) fix a desirable target clock frequency, and then (2) try to pack as many operations into each clock cycle as possible, ensuring that no cycle has a critical path that is too long for the target frequency. This is a matter of scheduling, and it might end up producing Verilog that looks (roughly) like this:
initial state = 0;
always @ (posedge clk)
case (state)
0: begin c = a * b;
e = c + d;
f = a * d;
state = 1; end
1: begin g = e * b; end
endcase
and which executes, in two clock cycles, like this:
This design probably offers the best compromise between minimising the number of clock cycles and maximising the clock frequency. And better still, if it can be determined that the value of c is not actually used except to hold the intermediate calculation a*b, then we can use an efficient fused multiply-add operator, like so:
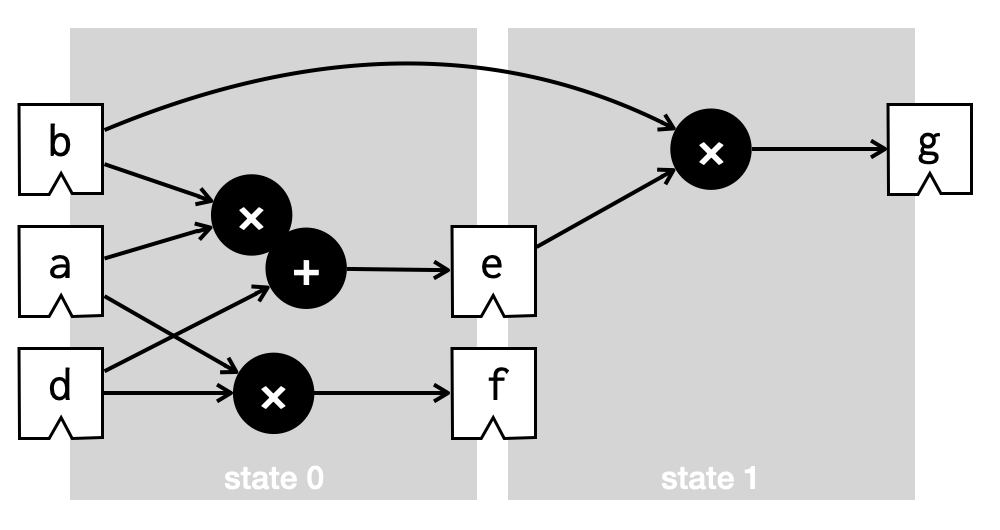
We thus arrive at the first contribution of Vericert v2.0: list scheduling. This is an optimisation that takes each basic block of the C code, and decides how best to chunk it up into clock cycles, taking account of the estimated delay of each operation.
However, existing HLS tools go further than this.
The thing is, list scheduling only deals with straight-line code, like in our example. We’d prefer also to optimise code that has more interesting control flow, such as if-statements, like this:
f = a * d;
if (d > 0)
c = a * b;
else
g = b * c;
e = c + d;
List scheduling would approach that code as four separate basic blocks, each requiring a separate state in the Verilog state machine. However, if we perform a process called if-conversion then we end up with what is known as a hyperblock. A hyperblock is a basic block where each instruction is guarded by a predicate, and an instruction executes only if its predicate evaluates to true. If-conversion on the code above might yield the following hyperblock:
true => f = a * d;
d > 0 => c = a * b;
d <= 0 => g = b * c;
true => e = c + d;
We’re back to straight-line code, and can hence can apply our scheduling approach once again to see how many operations we can safely pack into each clock cycle. But our scheduler must now be a hyperblock scheduler, which means that it must deal with predicates correctly. For instance, it must take account of the fact that the predicates d > 0 and d <= 0 are mutually exclusive, so the assignments to c and g can’t both occur, and can hence be scheduled for the same clock cycle (and even for the same multiplication unit).
So that’s the essence of Vericert v2.0 – Vericert v1.0 with a hyperblock scheduler, and everything still mechanically proven correct in Coq. Vericert v2.0 is still not truly competitive with state-of-the-art unverified HLS tools, as there are still many more optimisations that it doesn’t perform, but our performance evaluation indicates that when a state-of-the-art open-source HLS tool called Bambu is restricted to use only the optimisations that Vericert v2.0 knows about, the two tools perform quite similarly. And what’s nice about Yann’s proof is that it is completely independent of how the scheduler is implemented – he confirms that each schedule produced is correct, using a Coq-verified checker, but carefully ignores how the scheduler works. This means that the scheduler can be tweaked over time without needing to revisit the correctness proof.

[…] 详情参考 […]
Congratulations on the extremely cool work!
Thanks Jeehoon!
I’d be interested to see benchmarks against an HLS tool that uses SDC scheduling (linear programming). I worked on XLS which does. Though we found that switching from our previous min-cut based scheduler to the SDC scheduler did not really improve any of our internal or external benchmarks by much — we did it mostly to allow constraints to be passed in by the user. It looks like Bambu uses something SDC-based in their passes in at least one mode, but unclear if the actual scheduler is based on linear programming using integral constraints.
In XLS we handled the mutual exclusion aspect by simply having people not write code like that. But we still cared about mutual exclusion because of the following optimization: if you have input code that looks like mux(k, [f(x), f(y)]), you can translate this to f(mux(k, [x, y])). II > 1 also creates mutual exclusion similar to this (everything is under a mux that is connected to a looping counter). And if there are nested muxes with selectors that are dependent on each other in complicated ways, then you might want to build up a full mutual exclusion graph showing when two expressions are needed based on the muxes that dominate them (this requires invoking an SMT solver n^2 times, which is fairly practical if you set a time/resource limit). I never really figured out a good way to make a scheduler that exploits all of this before I left Google. You need something that solves the problem of finding the way to compress a term maximally via extracting out function calls (this is similar to, but different from, CSE, because you’re extracting out contiguous subgraphs rather than subtrees).