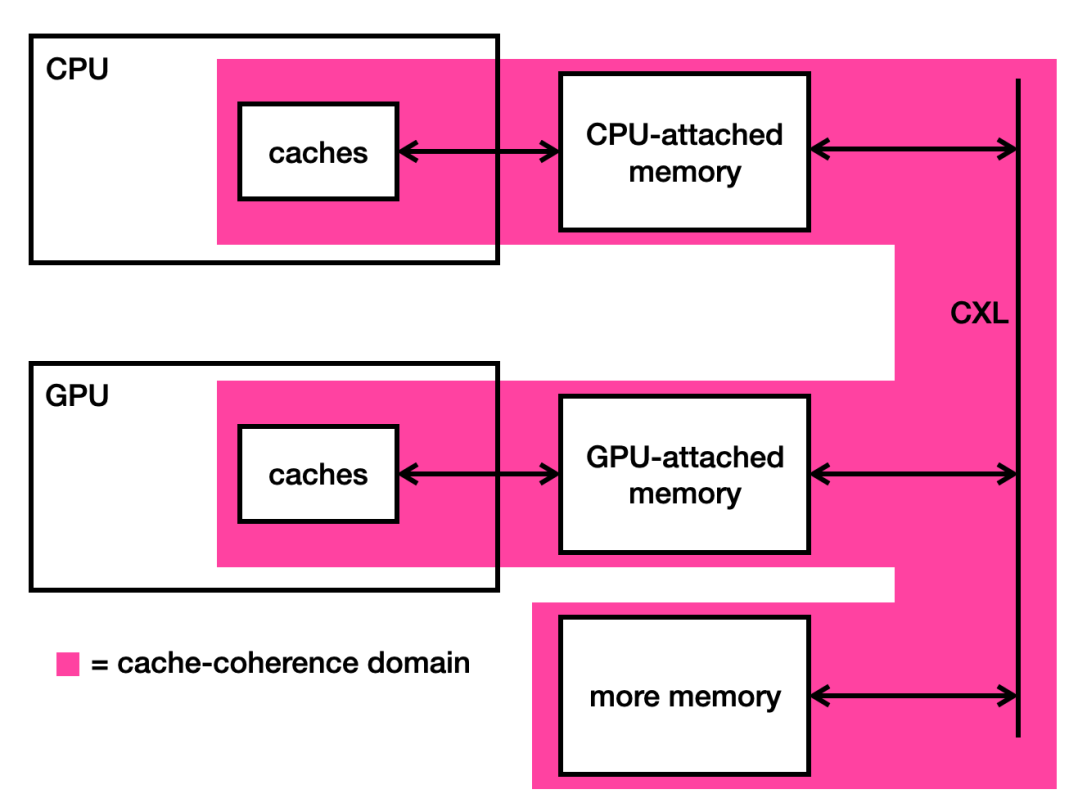
The world of computer architecture is quite excited these days about something called Compute Express Link (CXL). It’s a new standard that allows the various components of a datacentre computer to communicate large amounts of data efficiently with each other.
In this article, I’ll explain what CXL is, and why there is so much excitement about the possibilities that it opens.
I’ll start by talking about the situation before CXL came along.
The Way Things Are
We are in the age of parallelisation and specialisation. That is, it’s no longer practical to push all our computation through a single processor that runs very quickly; instead, we have to spread our computation out across several processors, all running in parallel. These various processors need not be identical; indeed, there are advantages to having different kinds of processors, all specialised for different tasks, and arranging that the overall computation is split up so as to play to the strengths of the available processors. For instance, a CPU might be well suited for handling user interaction, while the task of iterating through a large array might be handed off to a GPU.
Of course, now that we have spread out our processors in this way, we need to ensure that the data that our processors need is in the right place at the right time. And since we are also in the age of Big Data, we have a lot of data to move around.
It’s not practical to keep all data in a single memory — the delay associated with each read or write would be intolerable. CPUs tackle this problem by using caches: locations that are likely to be needed soon are copied into small ‘cache’ memories that are fast to access. Cache-coherence protocols are employed to ensure that data in those copies remains in-sync with the contents of the main memory.
Cache-coherence works nicely within a single CPU, but what about our heterogeneous system made up of CPUs, GPUs, and other devices?
Let’s consider a simple heterogeneous system made up of a CPU and a GPU, as shown in the picture below.
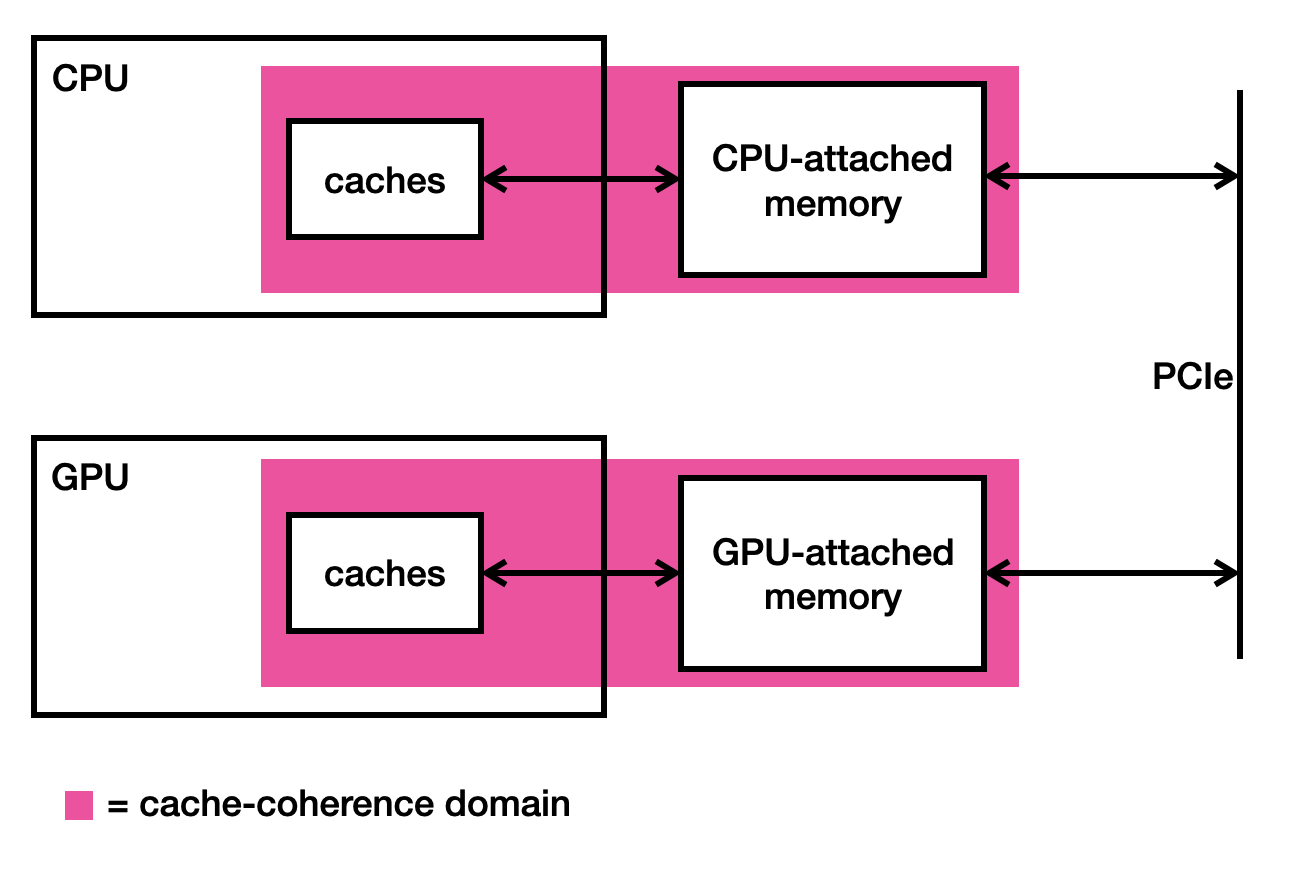
There are a couple of ways for the GPU to access data in the CPU’s memory. The traditional way is to copy data en-masse from the CPU’s memory into the GPU’s memory, and then to copy it back once the computation is complete. But this can involve an intolerable amount of data movement, much of which may be unnecessary.
An alternative is to give the GPU direct access to the locations in the CPU’s memory that it actually needs to read or write. This can reduce the amount of data flowing between the processors, but each individual memory access by the GPU now becomes very slow, because it has to go all the way to the CPU’s memory to get the freshest data. It cannot rely on copies of CPU memory locations that it may have stored in its own caches, because they may contain out-of-date values. After all, as shown in the picture above, the GPU is not part of the CPU’s cache-coherence domain, so it is not notified if the CPU overwrites a memory location that the GPU has cached.
The usual workaround is to ensure that the CPU does not access any of the memory locations to which the GPU has access until the GPU has finished with them. Naturally, this restricts what the CPU is able to do while the GPU is performing its task.
Enter CXL
The key idea of CXL is to extend the cache-coherence domain so that it covers not just the CPU, but all of the connected processors too. This gives us the following picture.
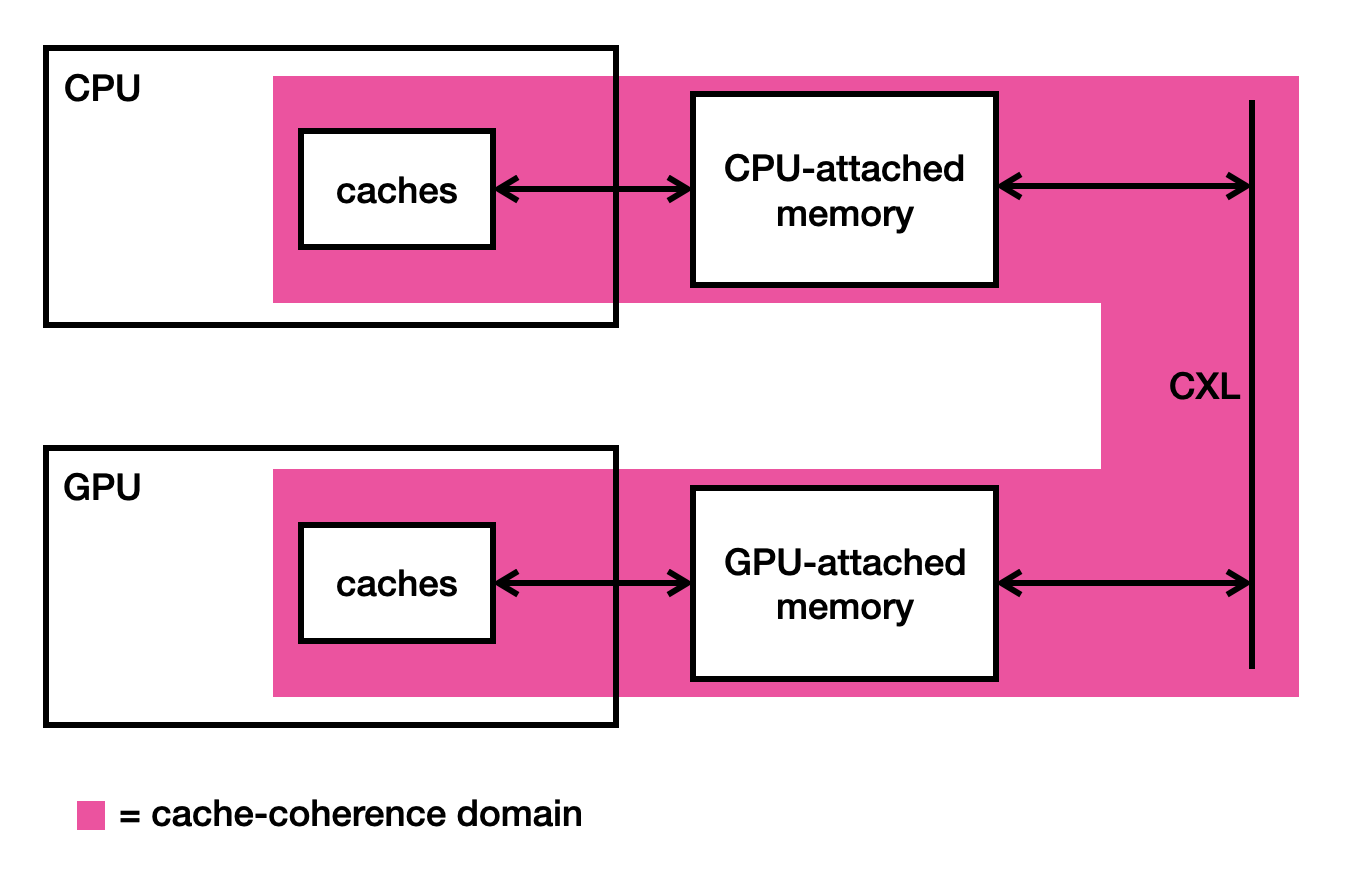
Why is this a good thing? Well, the CPU and the GPU can now cache any location in the CPU’s memory, safe in the knowledge that the cache-coherence protocol will notify them if the cached data goes out-of-date. There is no longer any need for the CPU to avoid memory locations that the GPU has been given access to.
So why wasn’t this done before? Well, it kinda was. For instance, AMD developed Infinity Fabric, which is used to provide a cache-coherent interconnect between AMD CPUs and AMD GPUs on Frontier, the fastest supercomputer in the world since 2020. Before that, NVIDIA developed NVLink, which did the same for IBM POWER9 CPUs and NVIDIA GPUs in Summit, the fastest supercomputer in the world before 2020. OpenCAPI is another cache-coherent interconnect protocol for IBM CPUs. The problem is that all of these protocols are vendor-specific. It is not possible to connect, for instance, an AMD CPU and an NVIDIA GPU, because the cache-coherence mechanisms used by one device are not meaningful to the other device.
One attempt that came close to being a vendor-independent standard was CCIX (Cache-Coherent Interconnect for Accelerators), which arose in the mid-2010s. It had the backing of several big players in the industry (AMD, Xilinx, Huawei, and Arm) but lacked broader support, most notably from Intel, and is now considered dead. CXL was proposed by Intel in 2019, and quickly attained broad support.
A Killer Application: Memory Pooling
As I’ve described above, CXL promises to make it easier for CPUs, GPUs, and other devices to communicate large amounts of data efficiently with each other.
But the CXL application that has the most industry buzz around it is called memory pooling.
Given that CXL can be used to allow devices to quickly access each other’s memory, the question arises: can we use CXL to connect devices that solely contain memory?
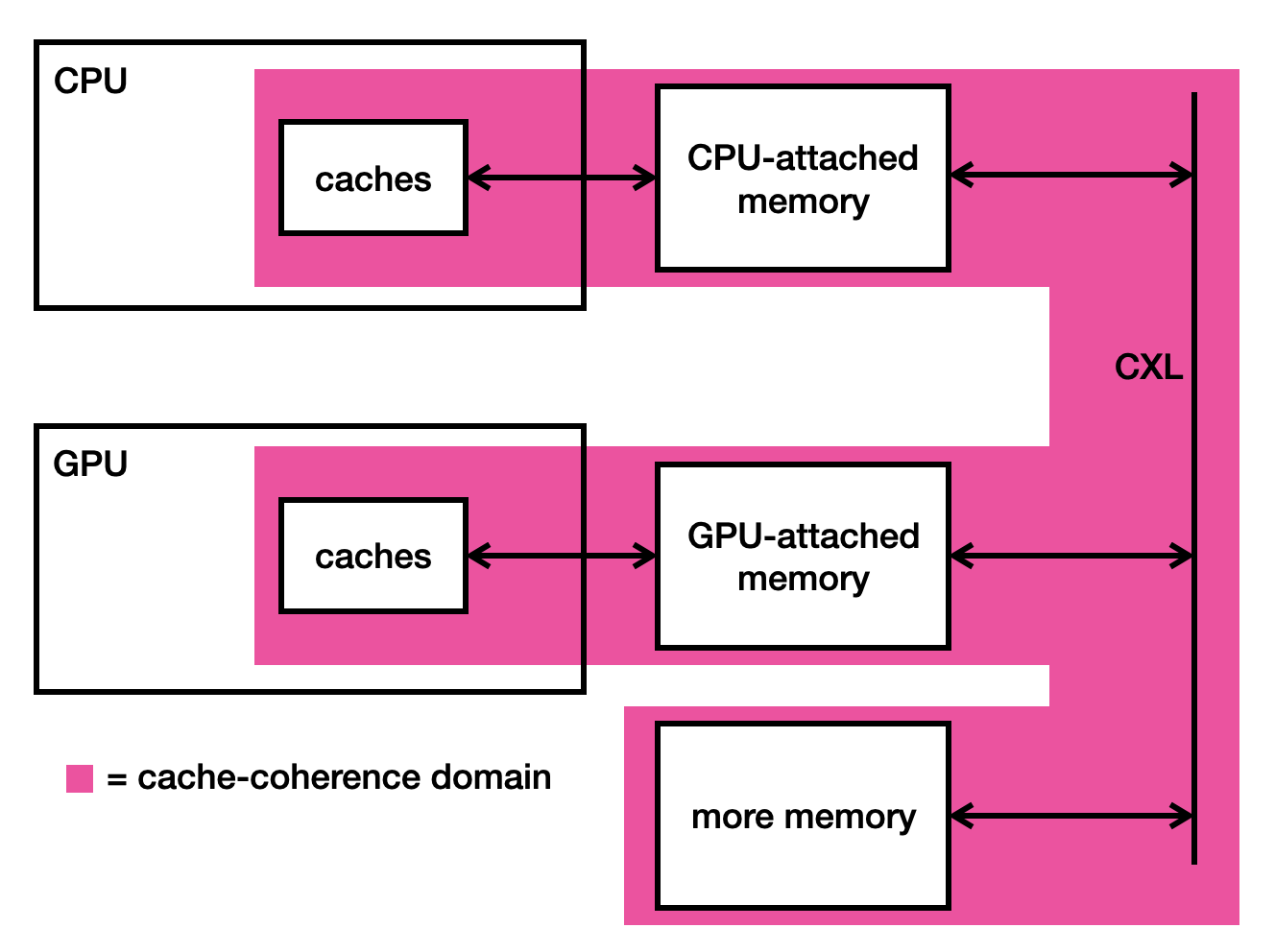
The picture above is enticing to a datacentre operator, because it shows how memory and processors can be disentangled. In our previous setup, each processor had a fixed amount of memory attached to it. This fixed amount had to be rather large, in order to suffice for the most memory-intensive workloads that the processor handles. But large amounts of memory are expensive, and anyway, most of that memory is likely unused most of the time.
But once we have CXL-connected memory, then this memory can be used by any processor that is also CXL-connected. It can be allocated to one processor for a while, then returned to the ‘pool’, and then allocated to a different processor that needs it. This can result in the system requiring far less memory attached to each processor, and hence far less memory overall, and hence substantial cost savings for the datacentre operator.
Sources and Further Reading
- “CXL Deep Dive” by Dylan Patel
- “CXL vs PCIe — A Brief Comparison” by Rajkapoor Singh
- “How CXL may change the datacenter as we know it” by Tobias Mann
- “Marvell CXL roadmap goes all-in on composable infrastructure” by Tobias Mann
- “How CXL 3.0 Fuels Faster, More Efficient Data Center Performance” by Gary Ruggles, Madhumita Sanyal, and Richard Solomon
